7. TaskScheduler的启动
第五节介绍了TaskScheduler的创建,要想TaskScheduler发挥作用,必须要启动它,代码:

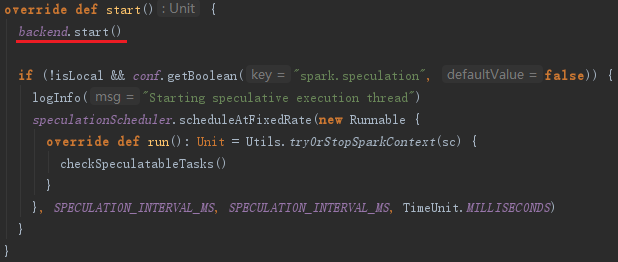
TaskScheduler在启动的时候,实际调用了backend的start方法,即同时启动了backend。local模式下,这里的backend是localSchedulerBackend。在TaskScheduler初始化时传入localSchedulerBackend。以LocalSchedulerBackend为例,启动LocalSchedulerBackend时向RpcEnv注册了LocalEndpoint。
7.1 创建LocalEndpoint
创建LocalEndpoint的过程主要是构建本地的Executor,见代码如下:
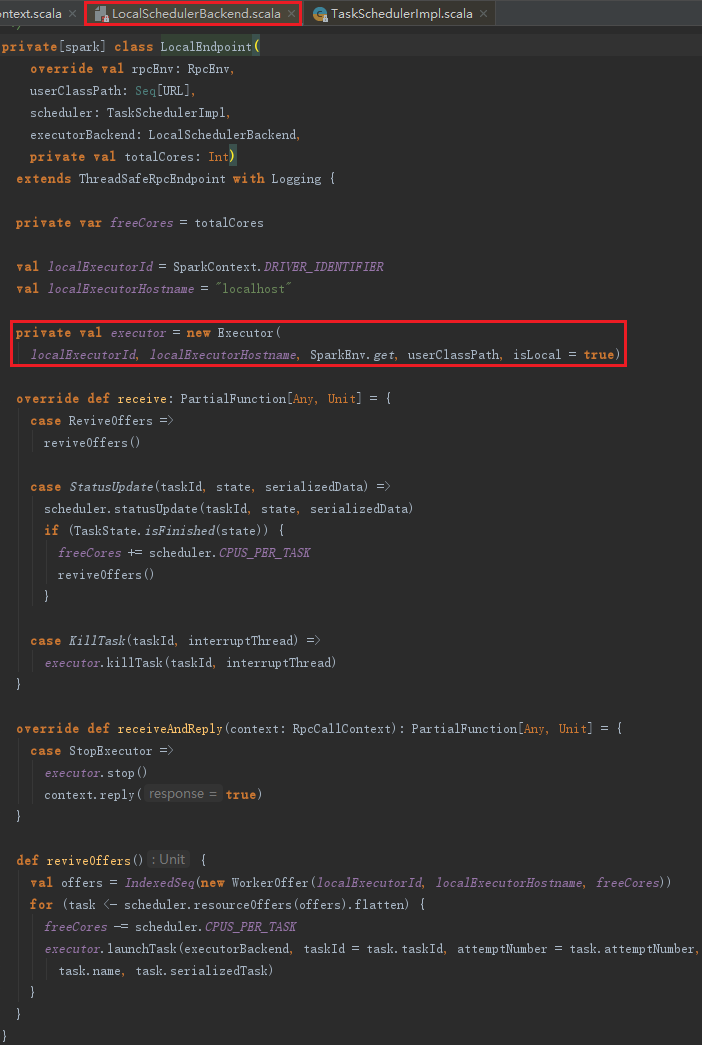
Executor的构建,主要包括以下步骤:
1) 创建并注册ExecutorSource。
2) 获取SparkEnv。如果是非local模式,Worker上的CoarseGrainedExecutorBackend向Driver上的CoarseGrainedExecutorBackend注册Executor时,则需要新建SparkEnv。可以修改属性spark.executor.port(默认为0,表示随机生成)来配置Executor中的RpcEnv的端口号。
3) urlClassLoader的创建。为什么需要创建这个ClassLoader?在非local模式中,Driver或者Worker上都会有多个Executor,每个Executor都设置自身的urlClassLoader,用于加载任务上传的jar包中的类,有效对任务的类加载环境进行隔离。
4) 创建Executor执行Task的线程池threadPool。此线程池用于执行任务。
5) 启动Executor的心跳线程heartbeater。此线程用于向Driver发送心跳。
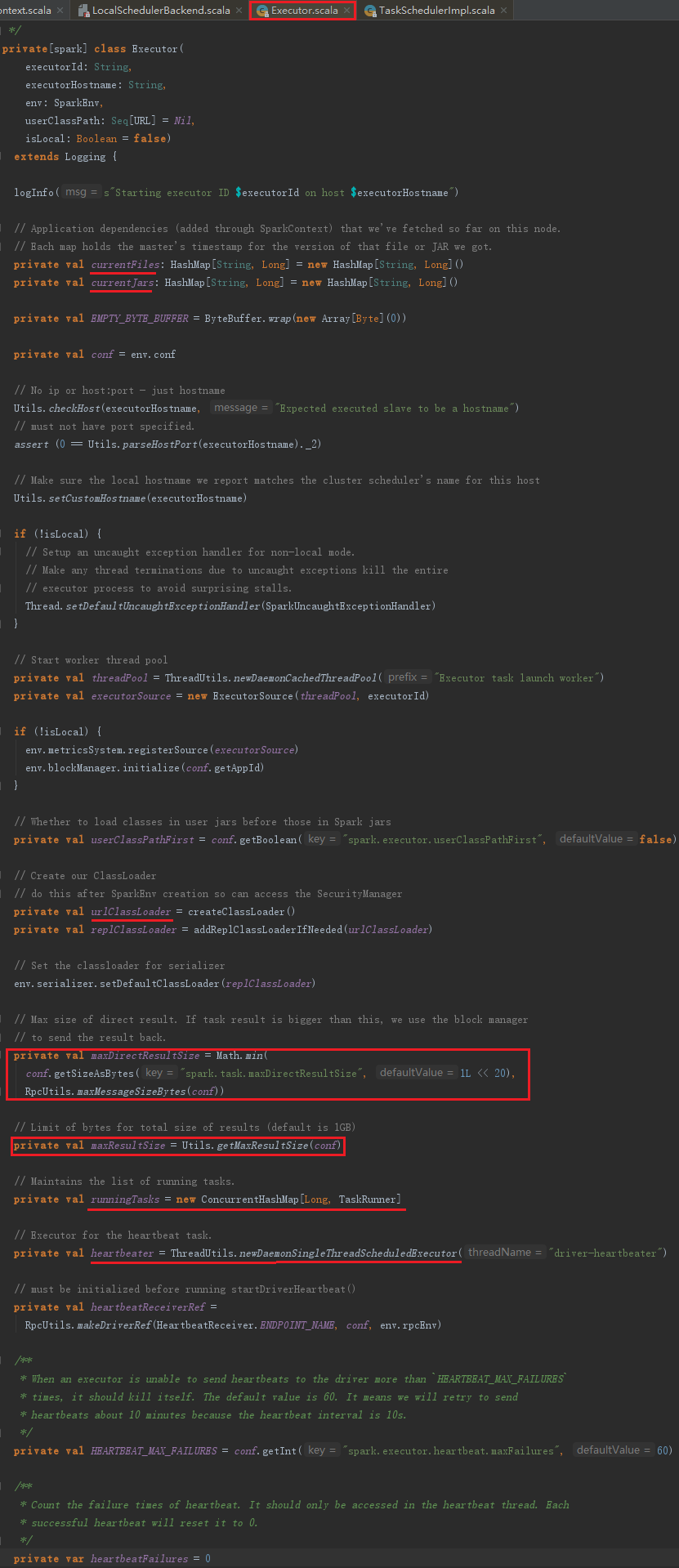
此外,还包括Rpc发送消息的帧大小(10485760字节)、结果总大小的字节限制(1073741824字节)、正在运行的task的列表、设置serializer的默认ClassLoader为创建的ClassLoader等。
7.2 ExecutorSource的创建与注册
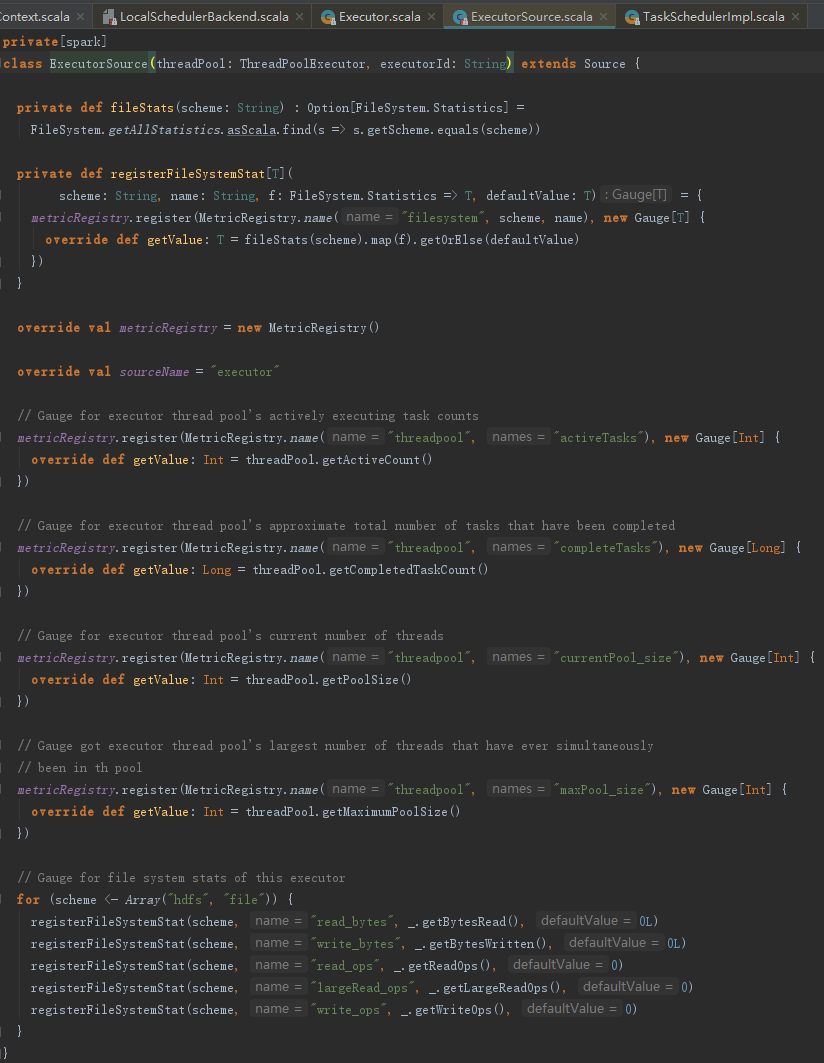
ExecutorSource用于测量系统。通过metricRegistry的register方法注册计量,这些计量信息包括threadpool.activeTasks、threadpool.completeTasks、threadpool.currentPool_size、threadpool.maxPool_size、filesystem.hdfs.write_bytes、filesystem.hdfs.read_ops、filesystem.file.write_bytes、filesystem.hdfs.largeRead_ops、filesystem.hdfs.write_ops等,ExecutorSource的实现见代码:
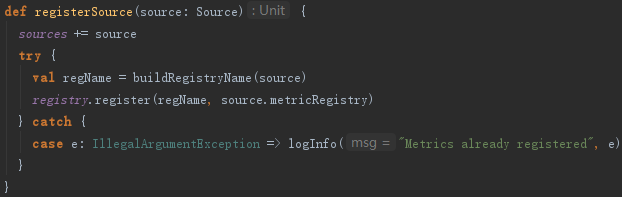
创建完ExecutorSource后,调用MetricsSystem的registerSource方法将ExecutorSource注册到MetricsSystem。registerSource方法使用MetricRegistry的register方法,将source注册到MetricRegistry,见代码:
7.3 Spark自身urlClassLoader的创建
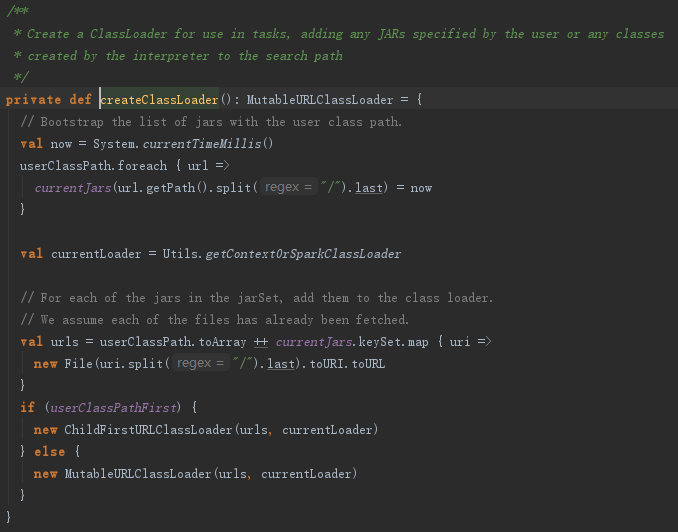
获取要创建的ClassLoader的父加载器currentLoader,然后根据currentJars生成URL数组,spark.files.userClassPathFirst属性指定加载类时是否先从用户的classpath下加载,最后创建ExecutorURLClassLoader或者ChildExecutorURLClassLoader,见代码:

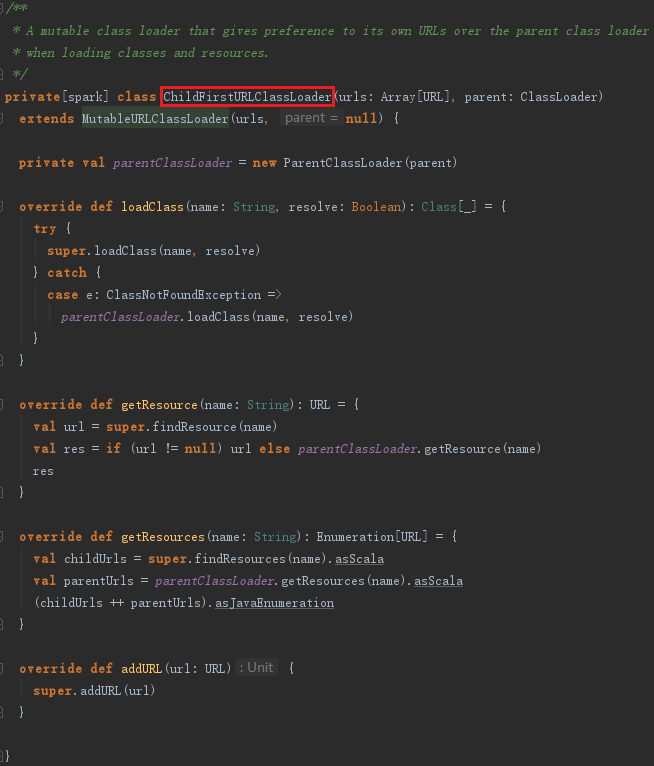
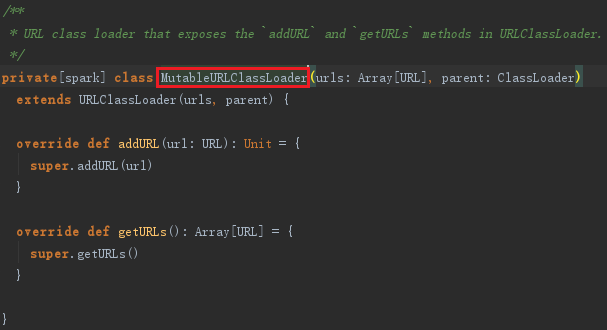
MutableURLClassLoader或者ChildFirstURLClassLoader实际上都继承了URLClassLoader,见代码:
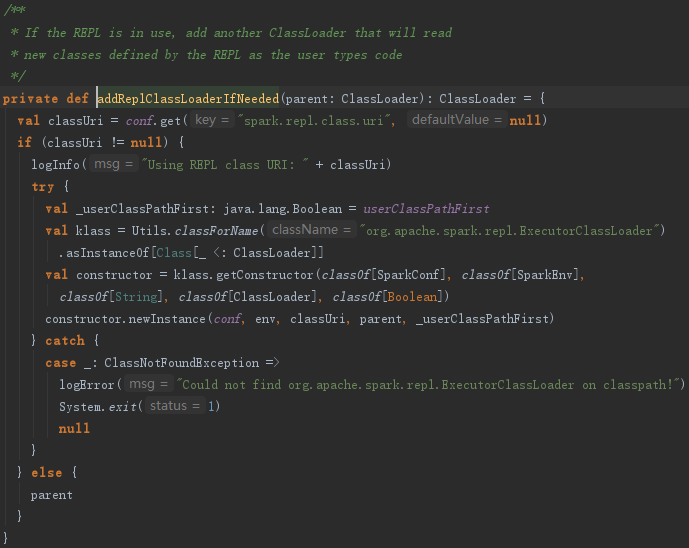
如果需要REPL交互,还会调用addReplClassLoaderIfNeeded创建replClassLoader,见代码:
7.4 启动Executor的心跳线程
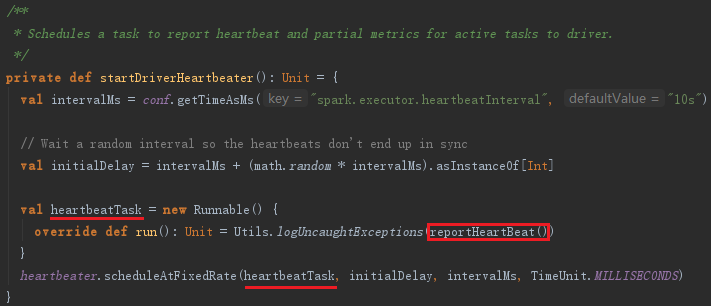
Executor的心跳由startDriverHeartbeater启动。Executor心跳线程的间隔由属性spark.executor.heartbeatInterval配置,默认是10000毫秒。此外,超时时间是30秒,超时重试次数是3次,重试间隔是3000毫秒。此线程从runningTasks获取最新的有关Task的测量信息,将其与executorId、blockManagerId封装为Heartbeat消息,向HearbeatReceiverRef发送Heartbeat消息。
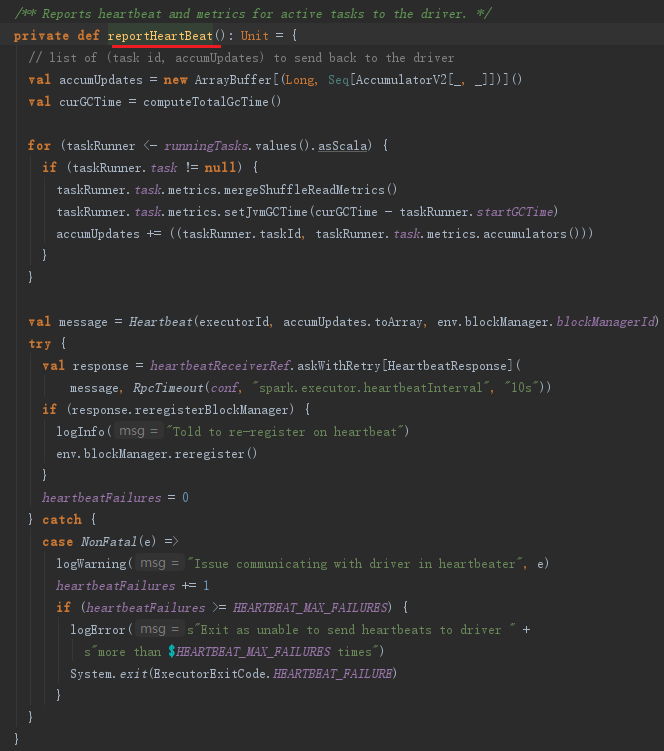
这个心跳线程的作用是什么呢?其作用有两个:
- 更新正在处理的任务的测量信息;
- 通知BlockManagerMaster,此Executor上的BlockManager依然活着。
下面对心跳线程的实现详细分析下:
初始化TaskSchedulerImpl后会创建心跳接收器HeartbeatReceiver。HeartbeatReceiver接收所有分配给当前Driver Application的Executor的心跳,并将Task、Task计量信息、心跳等交给TaskSchedulerImpl和DAGScheduler作进一步处理。创建心跳接收器的代码如下:

HeartbeatReceiver在收到心跳信息后,会调用TaskScheduler的executorHeartbeatReceived方法,代码如下:
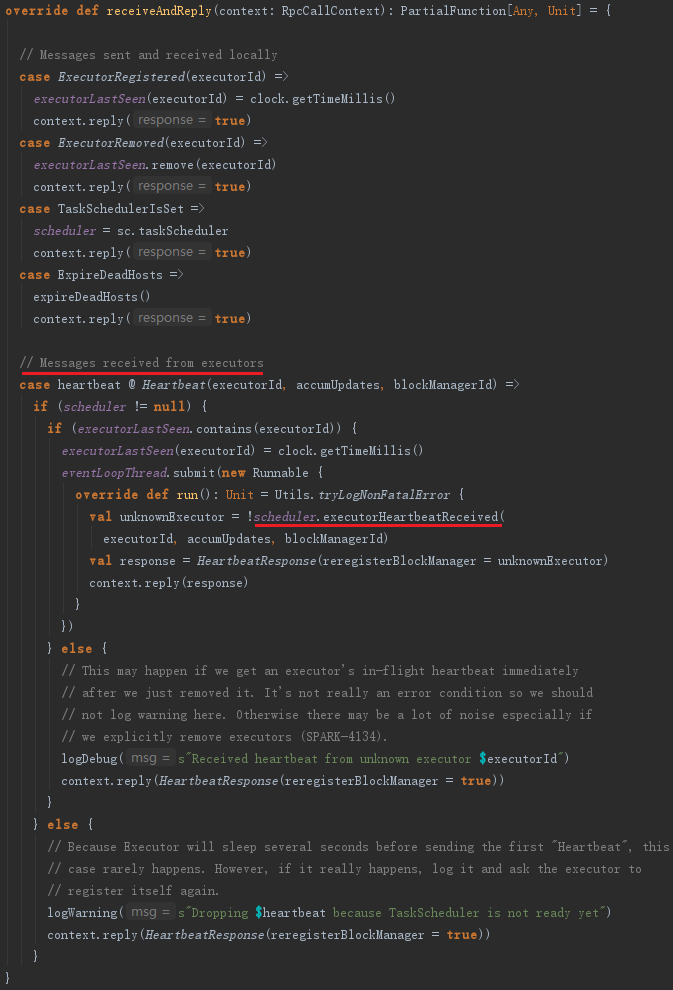
executorHeartbeatReceived的实现代码如下:
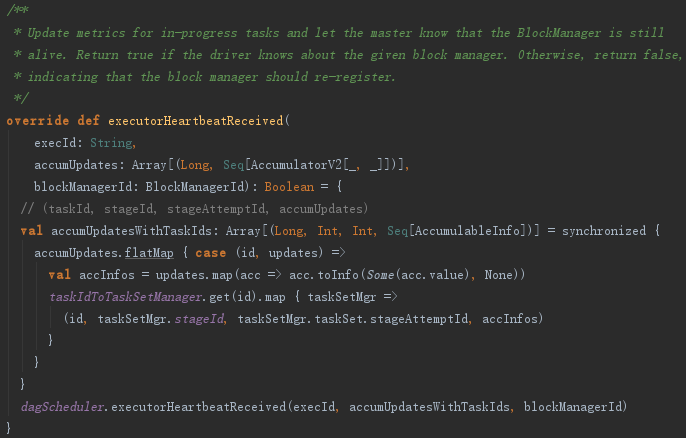
这段程序通过遍历accumUpdates,依据taskIdToTaskSetId找到TaskSetManager。然后将taskId、TaskSetManager.stageId、TaskSetManager.taskSet.stageAttemptId、accInfos封装到类型为Array[(Long, Int, Int,Seq[AccumulableInfo])]的数组accumUpdatesWithTaskIds中。最后调用了dagScheduler的executorHeartbeatReceived方法,其实现如下:
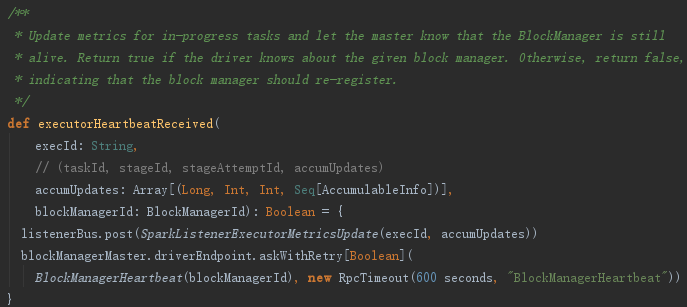
dagScheduler将executorId、accumUpdates封装为SparkListenerExecutorMetricsUpdate事件,并post到listenerBus中,此事件用于更新Stage的各种测量数据。最后给BlockManagerMaster持有的BlockManagerMasterEndpoint发送BlockManagerHeartbeat消息。BlockManagerMasterEndpoint在接收到消息后会匹配执行heartbeatReceived方法。heartbeatReceived最终更新BlockManagerMaster对BlockManager的最后可见时间(即更新BlockManagerId对应的BlockManagerInfo的_lastSeenMs)。